SQLAlchemy로 Python에서 ORM 사용하기
SQLAlchemy로 Python에서 ORM을 사용하는 방법
1. SQLAlchemy 기반 ORM의 기초¶
Java의 경우에는 JPA에 ORM Spec이 정의되어 있고 개발자는 JPA의 구현체인 Hibernate를 사용해 ORM을 사용하는 것처럼, Python은 PEP 249에 ORM Spec이 정의되어 있다.
Python은 Django의 경우 자체적인 ORM 엔진을 사용하고, 그 외의 경우에는 대부분 SQLAlchemy라는 패키지를 이용해서 ORM을 사용한다. 공식 문서에 따르면 SQLAlchemy는 아래와 같은 DB들을 지원하는데, 각 데이터베이스가 지원하는 드라이버와 조합하여 사용할 수 있다.
Tip
각 데이터베이스의 드라이버의 목록을 보면 여러 가지가 있는데, 비동기처리를 DB I/O에까지 적용하려면 Async를 지원하는 DB 및 드라이버를 사용해야한다.
대표적으로 Microsoft SQL Server의 경우 SQLAlchemy가 지원하는 드라이버는 pymssql와 PyODBC가 있는데, 둘 다 비동기처리를 지원하지 않는다.
2. 데이터베이스 엔진 생성¶
엔진은 SQLAlchemy 애플리케이션의 시작점으로, 아래 그림과 같이 Connection Pool과 Dialect를 연결하여 데이터베이스 연결 및 동작을 위한 소스를 생성해준다.
Note
컨넥션 풀이란 데이터베이스에 접속하는 객체를 일정 갯수로 생성하여 재활용하며 사용하는 것을 말한다.
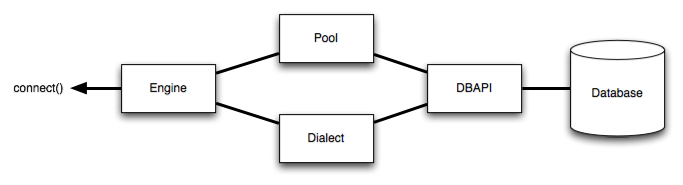
SQLAlchemy는 데이터베이스를 엔진 방식으로 사용함으로서 데이터베이스에 접속하는 세션 수를 제어하고, 세션 접속에 소요되는 시간을 줄일 수 있다고 한다.
SQLAlchemy 엔진에 데이터베이스 주소를 설정해줘야 하는데, 해당 주소는 아래와 같은 규칙으로 이루어져 있다.
Tip
데이터베이스 주소는 :, /, @등을 구분자로 사용하기 때문에 비밀번호 등에 해당 특수문자가 있을 경우 주소를 제대로 인식하지 못하는 문제가 있다.
이런 문제를 방지하기 위해서는 해당 정보를 urllib.parse 클래스로 인코딩 해서 입력해도 되고, URL.create() 함수를 사용해서 주입해줘도 된다.
Note
DB URL에 대한 자세한 내용은 SQLAlchemy 공식 문서를 참고하자.
SQLAlchemy의 데이터베이스 엔진을 생성하는 방법은 아래와 같다.
from contextlib import contextmanager
from pathlib import Path
import yaml
from addict import Dict
from sqlalchemy.engine import URL, create_engine
from sqlalchemy.orm import sessionmaker
RESOURCES = Path("resources")
with open(RESOURCES / "config.yaml", encoding="utf-8") as f:
config = Dict(yaml.load(f, Loader=yaml.SafeLoader))
db_config = config.db
DB_URL = URL.create(**db_config.url)
engine = create_engine(
url=DB_URL,
**db_config.engine,
)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
@contextmanager
def get_db():
db = SessionLocal(bind=engine)
try:
yield db
finally:
db.close()
from contextlib import asynccontextmanager
from pathlib import Path
import yaml
from addict import Dict
from sqlalchemy.engine import URL
from sqlalchemy.ext.asyncio import AsyncSession, create_async_engine
RESOURCES = Path("resources")
with open(RESOURCES / "config.yaml", encoding="utf-8") as f:
config = Dict(yaml.load(f, Loader=yaml.SafeLoader))
db_config = config.db
DB_URL = URL.create(**db_config.url)
engine = create_async_engine(
url=DB_URL,
**db_config.engine,
)
@asynccontextmanager
async def get_db():
db = AsyncSession(bind=engine)
try:
yield db
finally:
await db.close()
db:
url:
drivername: mysql+aiomysql
username: qwer
password: asdf
host: localhost
port: 3306
database: test
engine:
pool_pre_ping: true
pool_recycle: 3600
echo: false
Tip
engine 생성 시에 echo=true 옵션을 주면 터미널에 SQLAlchemy 엔진의 로그가 출력 된다.
다만 Flask나 Gunicorn 등 자체적인 로거가 있는 애플리케이션에서 SQLAlchemy를 사용할 때 echo=true 옵션을 사용한다면 SQLAlchemy의 로거와 상위 애플리케이션의 로거가 로그를 중복되게 출력하는 버그가 있다. 이 버그는 아래와 같이 SQLAlchemy의 로거가 NullHandler로 로그를 다루도록 설정해서 해결할 수 있다.
import logging
from sqlalchemy.engine import URL
from sqlalchemy.ext.asyncio import AsyncSession, create_async_engine
from src.core import configs
config = configs.config
logging.getLogger("sqlalchemy.engine.Engine").addHandler(logging.NullHandler())
DB_URL = URL.create(**config.db.url)
db_engine = create_async_engine(
url=DB_URL,
**config.db.engine,
)
3. 엔진 활용¶
SQLAlchemy 엔진을 활용해서 DB에 접속하는 방법은 아래와 같다. get_db 함수를 굳이 추가로 만들어 사용하는 이유는, DB 쿼리에서 오류가 발생하더라도 반드시 해당 커넥션이 커넥션 풀로 반환되도록 하기 위해서이다.
import asyncio
from sqlalchemy.sql import select
from src.db.database import engine, get_db
async def main():
async with get_db() as db:
q = select(1)
res = await db.execute(q)
result = res.scalar()
print(result)
await engine.dispose() # (1)!
if __name__ == "__main__":
asyncio.run(main())
- DB I/O에 비동기 처리를 사용할 때만 필요